Fluxo de trabalho com targets
Gabriel Nakamura
2024-07-16
Apresentação
Algumas análises são extremamente demoradas para rodar, ou ainda apresentam muitos passos na sua execução. Desde a limpeza dos dados originais, transformações, múltiplas análises e apresentações destas análises através de figuras ou tabelas. Todo esse conjunto de ações quando tomadas em conjunto é o que chamamos de pipeline ou fluxo de trabalho. Devido a complexidade e tempo que este fluxo pode assumir é comum perdermos controle da sequência que cada tarefa deve ser executada.
Devido a isso, muitas vezes nos pegamos rodando nossos códigos de maneira repetida, e algumas vezes sem nem mesmo saber se precisamos rodá-los. Isso é o que chamamos de loop sisypheano. Ao invés de rolar uma pedra morro acima toda vez, o que fazemos é rodar as mesmas análises repetidamente.

Sisyphus rolando a pedra morro acima, para a eternidade. A principal diferença entre mim e Sisyphus são os músculos
Uma solução para quebrar o loop sisefeano e otimizar nosso fluxo de
trabalho é a utilização do pacote {targets}. A partir de
agora, esperamos que as únicas pedras rolantes que vamos nos deparar
sejam essa do vídeo abaixo.
O pacote {targets}
O pacote {targets} possibilita otimizar a sequência de
trabalho (pipeline) por organizar esta sequência e identificar ações no
fluxo de trabalho que devem ou não devem ser realizadas.
Exemplo
Para ilustrar o uso do pacote targets vamos utilizar um exemplo contido na própria documentação do pacote.
Neste exemplo vamos analisar a relação entre quantidade de ozônio e
temperatura em um conjunto de dados presentes no próprio R base chamado
airquality. Para tanto precisamos seguir uma sequência de
análise de dados, que, basicamente, consiste em:
Ler e manipular a tabela de dados
Rodar um modelo relacionando ozônio e temperatura
Gerar resultados gráficos (figuras) para o modelo ajustado
A base de dados pode ser lida da seguinte forma
Imagine que estes dados estão organizados em um diretório local inicializado a partir de um .Rproject e ele apresenta a seguinte estrutura:
Uma pasta
datacontendo os dadosUma pasta R contendo:
- script com a leitura e transformação dos dados
- script com o modelo
- script com funções para plotar os resultados do modelo ajustado
Esta seria uma pasta organizada, tal como vimos durante as aulas. Porém, para que o pacote targets funciona precisamos transformar esta estrutura de acordo com um pipeline targets, que por sua vez necessita da seguinte estrutura:

Neste diretório precisamos transformar a sequência apresentada
anteriormente em uma sequência de funções. Portanto os scripts na pasta
R serão transformados em funções que serão colocadas dentro da pasta R,
com o nome de functions.R, e que apresentará a seguinte
forma:

Veja que a mesma sequência de análise está agora representada como funções, naquilo que chamamos de uma pipeline function. Este formato é necessário pois apenas assim o targets irá funcionar.
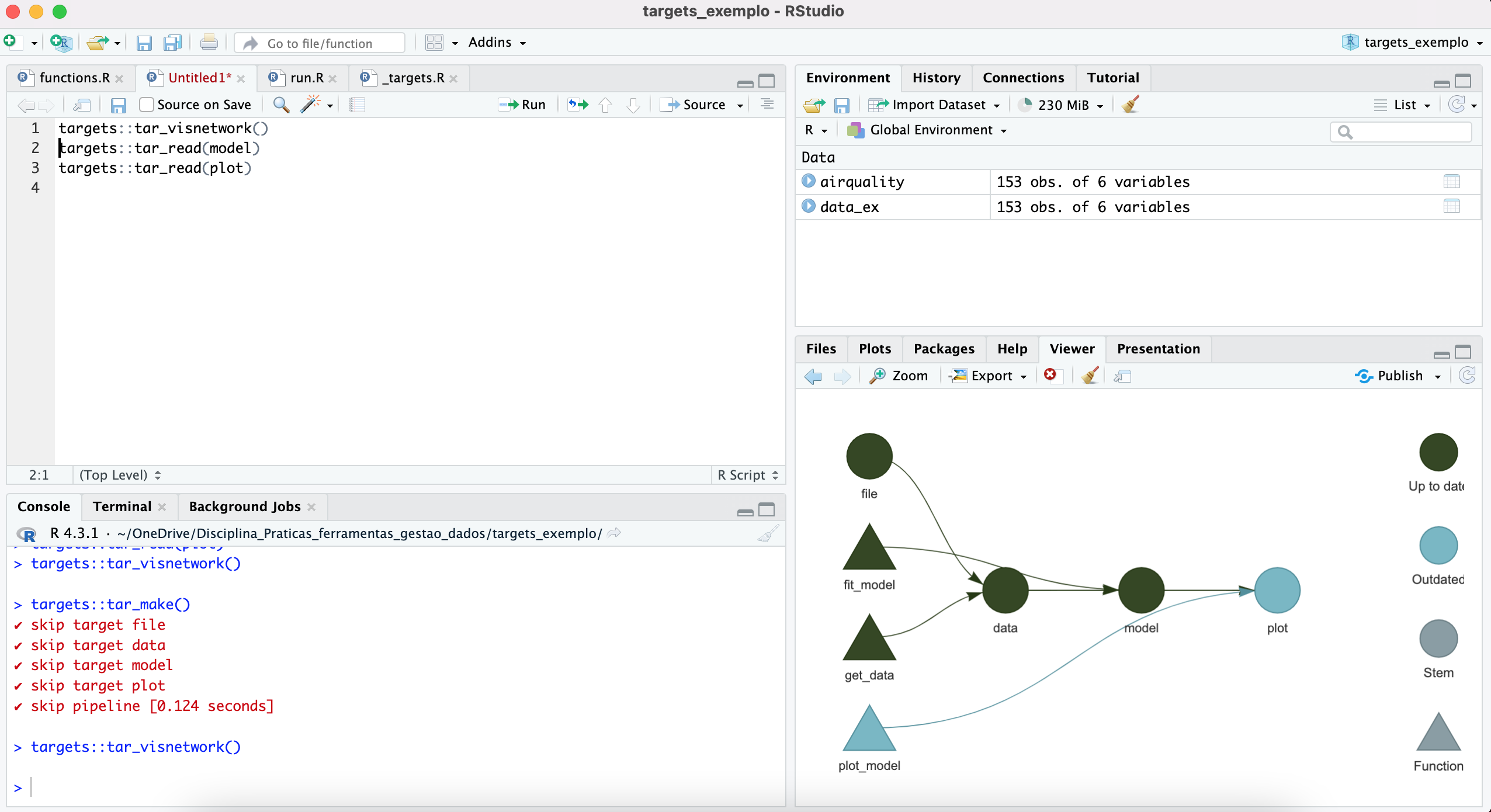
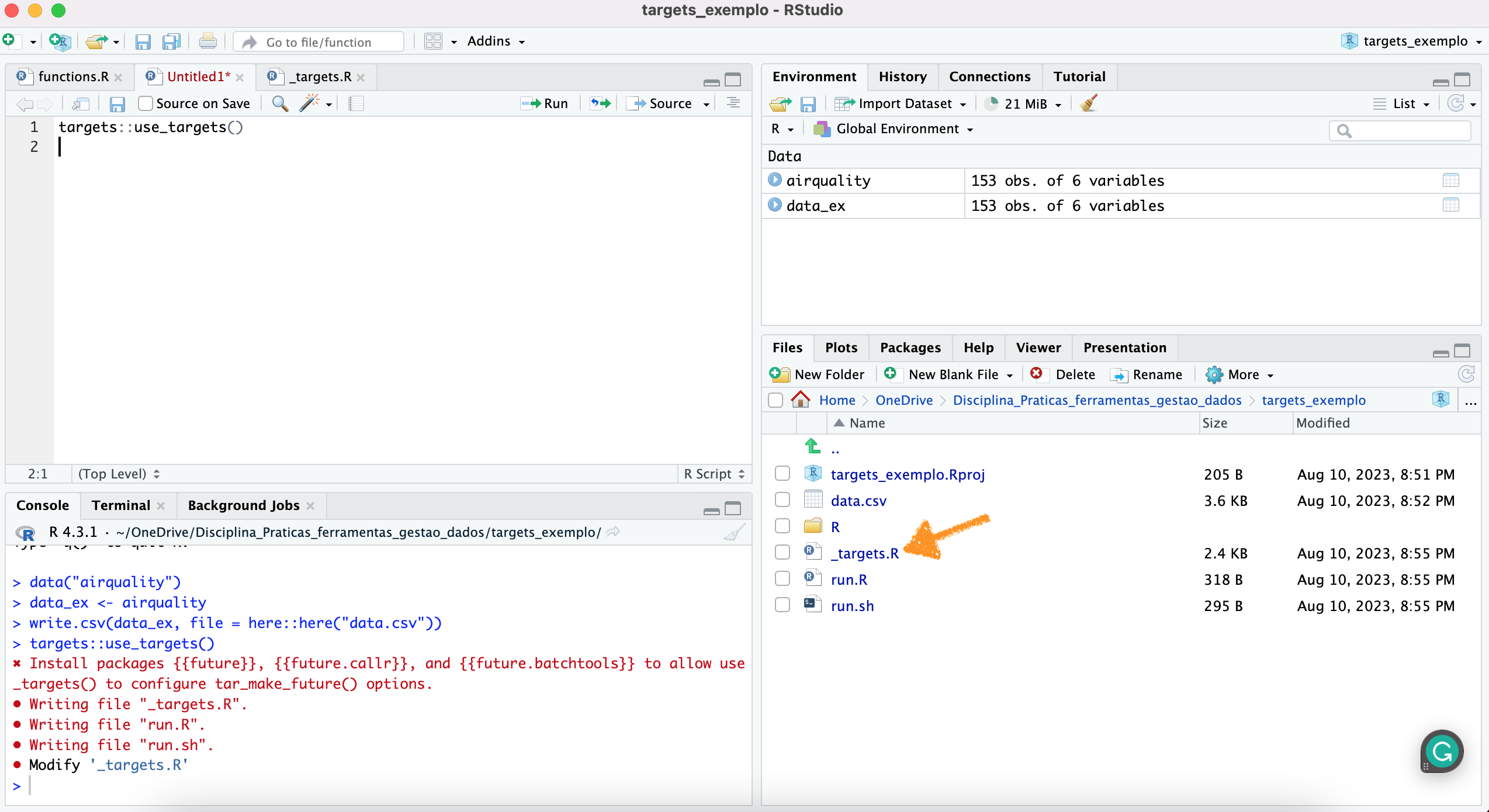
Uma vez organizado assim, devemos utilizar uma função do pacote targets para gerar um workflow do tipo target. Isso será feito da seguinte maneira:
Isso criará um documento na raiz do seu projeto denominado
_targets.R, como ilustrado na figura abaixo, que representa
um diretório que segue um workflow do targets
O documento criado informará a sequência do workflow de análise que o pacote targets deve seguir. Após editar o documento para este exemplo ele ficará da seguinte forma
# _targets.R file
library(targets)
source("R/functions.R")
tar_option_set(packages = c("readr", "dplyr", "ggplot2"))
list(
tar_target(file, "data.csv", format = "file"),
tar_target(data, get_data(file)),
tar_target(model, fit_model(data)),
tar_target(plot, plot_model(model, data))
)Neste exemplo o arquivo apresenta os seguintes componentes:
As funções necessárias para rodar o workflow
os pacotes necessários
uma lista que indica a sequência que o workflow deve obedecer
Para rodar o workflow via targets usamos a seguinte função
A sequência do workflow vai iniciar e o tempo decorrido vai aparecer no console

Visualizando o workflow
Uma das vantagens do target é que podemos visualizar a sequência do workflow e se ele está atualizado ou não. Para isso usamos a seguinte função
Esta função vai produzir um gráfico como mostrado nesta figura
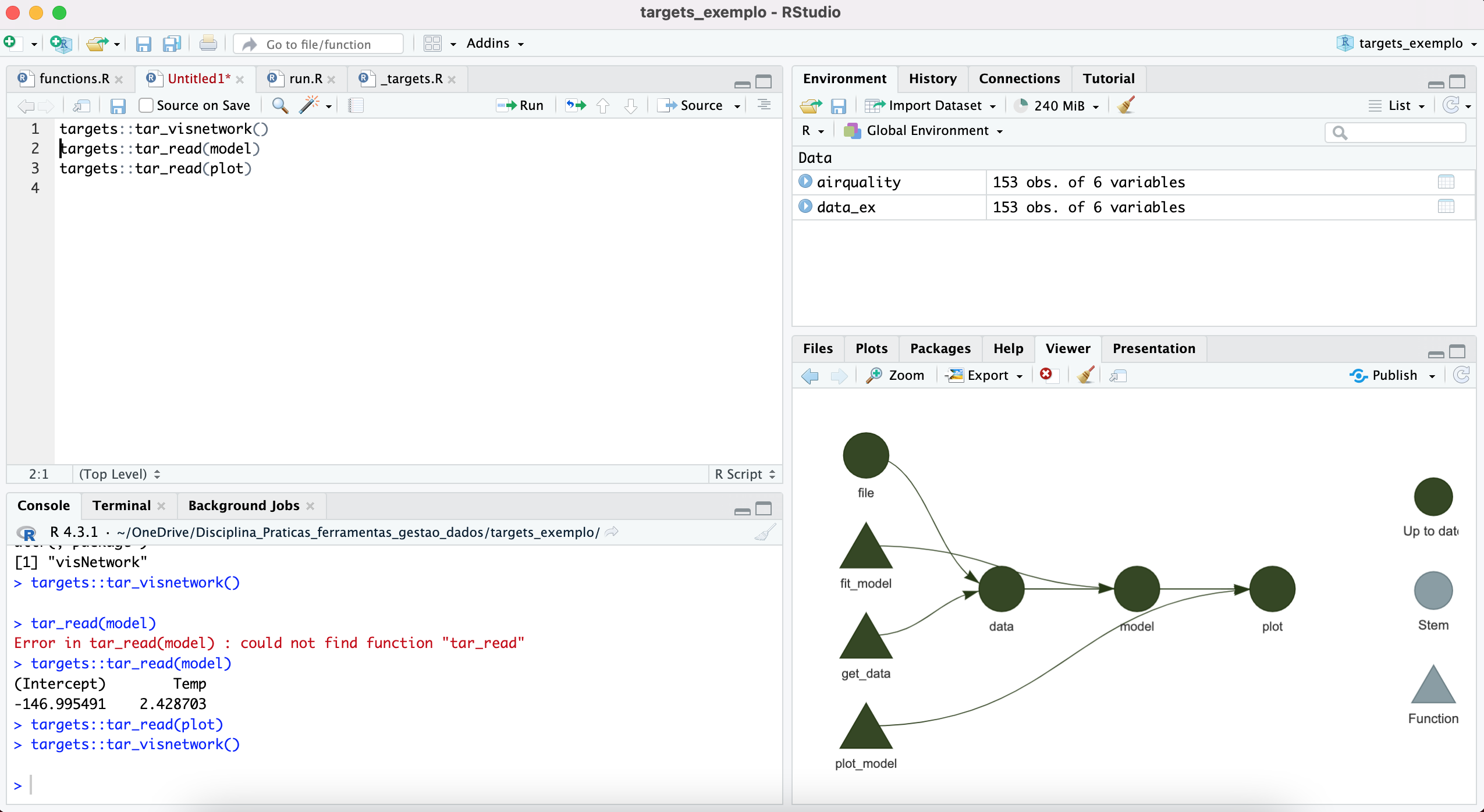
Podemos também acessar o output do workflow
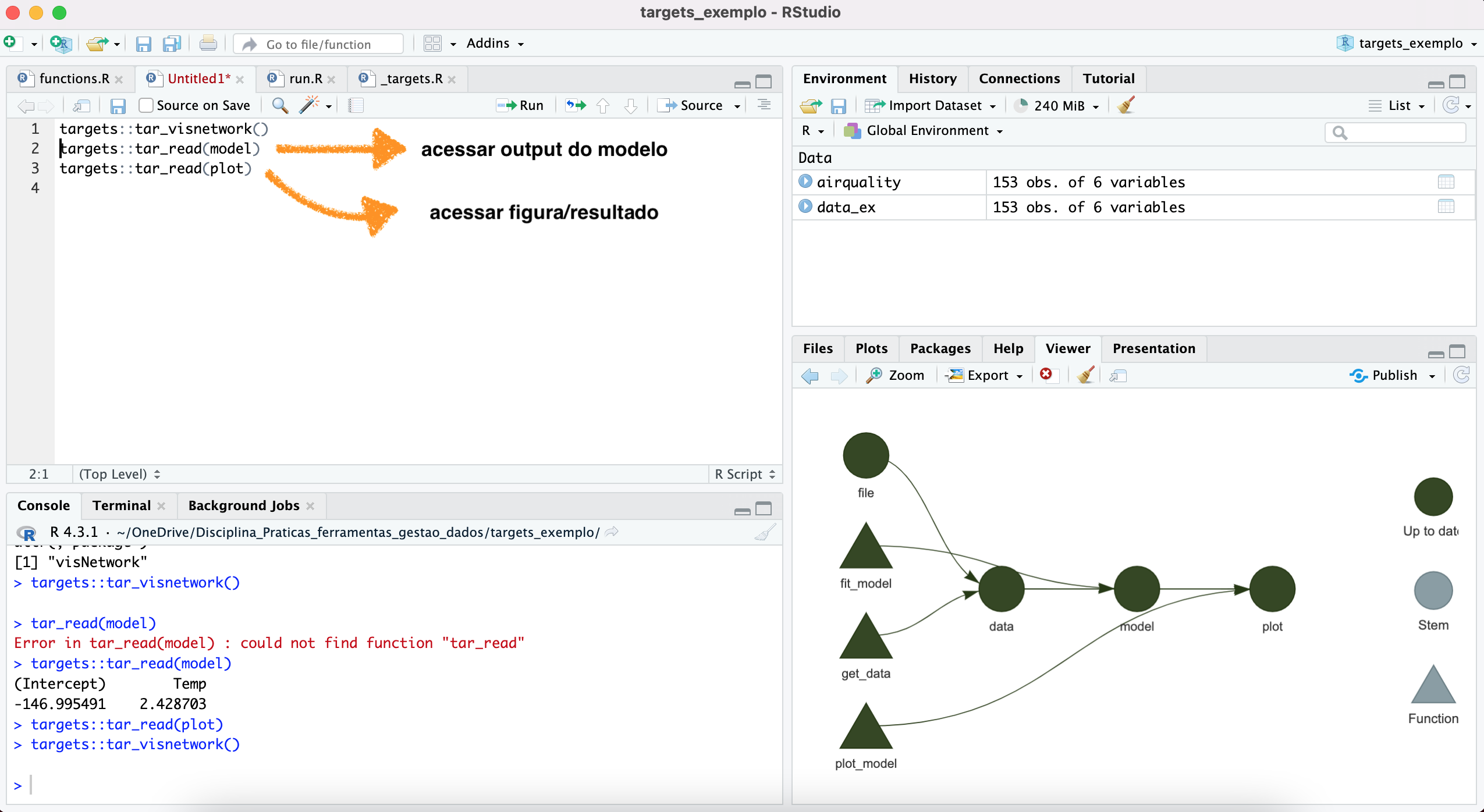
Identificando mudanças no workflow
Uma das maiores potencialidades do targets é identificar de maneira
eficiente partes do workflow que precisam ser rodadas novamente após
realizarmos mudanças na nossa pipeline. Por exemplo, vamos supor que
modificamos apenas um parâmetro que afeta a estética do plot final dos
resultados do modelo. Não necessitamos rodar tudo de novo, apenas a
figura resultante do modelo. O targets identifica onde esta modificação
foi feita e aponta a parte do workflow que precisa ser rodado novamente.
Podemos identificar isso através da função tar_viznetwork()
que vai gerar a seguinte figura (dado a situação descrita acima)