Organizando os scripts
Gabriel Nakamura
5/16/2021
Grande parte de um projeto científico consiste em realizar análises estatísticas, processamento de dados e geração de figuras. Portanto, ter scripts bem organizados e que possibilitam que outras pessoas possam seguir os mesmos passos realizados por você é de extrema importância para a reprodutibilidade.
Neste documento apresentarei funcionalidades do RStudio e alguns pacotes que auxiliam a organização das análises em scripts.
A primeira dica para um script reprodutível é, nunca faça isso:
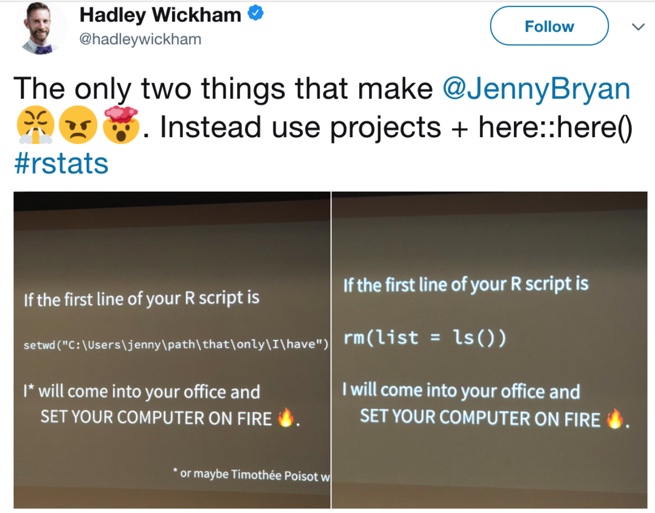 A seguir, outras dicas para que o Hadley não entre na sua casa e queime seu computador.
A seguir, outras dicas para que o Hadley não entre na sua casa e queime seu computador.
NUNCA USE ESSES COMANDOS
read.table(file.choose())
read.csv(file.choose())
read.csv2(file.choose())Espero esclarecer os porquês de não utilizar estes comandos após o término dessa leitura. Mas basicamente, a solução para um script organizado e reprodutivel tem uma formula simples:
Rproject + here = um script reprodutível
Os pecados capitais na organização e reprodutibilidade de dados
1 - Nunca utilize caminhos absolutos
Quem nunca se deparou com dificuldades para leitura de dados? Isso é um problema frequente, ainda mais quando estamos começando a nos familiarizar com o R. A primeira dica do que nunca fazer é não utilizar caminhos absolutos para leitura de dados. Por que?
Caminhos na linguagem da computação corresponde ao trajeto que o programa deve fazer para acessar um determinado arquivo. Um caminho absoluto quer dizer que passamos para o programa o caminho completo para acessar o arquivo desejado, ou seja, desde a base do trajeto até o local do arquivo desejado. Por exemplo, o que está no código seguinte:
read.table("/Users/gabrielnakamura/OneDrive/Aulas/Disciplina_ppgEco/Curso_UFRGS_organizacao_de_dados/nome_de_um_arquivo.txt") # caminho absoluto para acessar um arquivo deste cursoPor outro lado, um caminho relativo é um atalho. Ao invés de informar todo o caminho como acima, nós informamos para o programa apenas a parte deste caminho que ele desconhece, ignorando todo o resto que é conhecido, e, portanto, não precisa ser indicado. Por exemplo, o mesmo caminho do código anterior pode ser expresso em termos relativos como:
read.table("~/Curso_UFRGS_organizacao_de_dados/nome_de_um_arquivo.txt") # caminho relativo para acessar um arquivo deste cursoPor que utilizar o caminho relativo
Para responder a essa questão basta pegar um código escrito por outra pessoa que usa caminhos relativos em seus scripts e tentar rodar na sua máquina. O que vai acontecer? Uma mensagem de erro. Falhamos na reprodutibilidade por não conseguir ler os dados.
Isso acontece pois o caminho absoluto na sua máquina não é o mesmo caminho absoluto da minha, ou de qualquer outra pessoa, a não ser por uma coincidência absurdamente improvável. A solução para esse problema é a utilização do caminho relativo. O caminho relativo é passível de reprodução pois assume-se que a pessoa que está usando aquele conjunto de dados tenha exatamente todos os arquivos presentes no repositório local (workdirectory) das análises. Para exemplificar, vamos fazer o seguinte exercício. Pegue o repositório de um dos colegas desse curso e tente ler algum arquivo a partir do caminho relativo. que geralmente segue esse formato:
read.table("~/nome_do_workdirectory/arquivo_a_ser_lido.txt")Ou se este arquivo estiver em alguma pasta dentro do seu workdirectory, por exemplo, dentro da pasta data depois dentro de processed
read.table("~/nome_do_workdirectory/data/processed/arquivo_a_ser_lido.txt")Caminhos relativos para os arquivos podem ser obtidos a partir do uso do RStudio, mais especificamente, utilizando uma ferramenta do RStudio chamada Rproject, ou simplismente Projeto. A mágica do Projeto do RStudio é transformar todo caminho em relativo, em termos mais simples, ele pega o caminho absoluto e transforma num atalho. Na prático, tudo o que precisa ser informado para leitura de qualquer arquivo agora é o caminho a partir do local onde o Projeto do RStudio se encontra. Por exemplo, vamos ler o arquivo dados_test que pode ser obtido baixando o repositório GabrielNakamura/MS_FishPhyloMaker através do código:
download.file(url = "https://github.com/GabrielNakamura/MS_FishPhyloMaker/archive/master.zip", destfile = "MS_FishPhyloMaker.zip") # para baixar
unzip(zipfile = "MS_FishPhyloMaker.zip") # para unziparA pasta vai ser baixada e extraída para o seu atual diretório, não se preocupe com isso nesse momento, o exercício serve apenas para mostrar como utilizar caminhos relativos para leitura de dados para dentro do R.
Temos três opçoes:
- Opção 1: Errado
setwd("~/OneDrive/Manuscritos/MS_FishPhyloMaker_") # primeiro especificando o diretório
raw_data <- read.csv("~/data/osm-raw-data.csv", sep=";") # agora lendo os dadosIsso é uma opção, mas lembre-se que Jenny Bryan irá entrar no seu escritório e queimar seu computador. Logo, não parece uma boa opção.
{kind=link}
- Opção 2: Errado
Não queremos que ninguém queime nosso computador, então podemos tirar o set_wd e utilizar o caminho absoluto
raw_data <- read.csv("/Users/gabrielnakamura/OneDrive/Manuscritos/MS_FishPhyloMaker_/data", sep=";")Isso funcionaria, mas apenas no meu computador. Logo, falhamos na reprodutibilidade, e não queremos isso.
- Opção 3: Correto
raw_data <- read.csv(here::here("data", "osm-raw-data.csv"), sep=";")Todos conseguiram ler? Se sim, conseguimos atingir o primeiro passo para um trabalho reprodutível: Todos conseguem ler os dados, independente do computador que estivermos utilizando
Para conseguir a reprodutibilidade na leitura dos dados utilizamos duas ferramentas. O primeiro é o Rproject, que possibilitou a utilização do caminho relativo, por isso informamos apenas que o arquivo “osm-raw-data.csv” está na pasta “data”, pois o diretório raiz agora é aquele em que o projeto está hospedado. A segunda ferramenta que utilizamos foi o pacote {here}. A importância do pacote, além de simplificar a sintaxe pois precisamos apenas digitar o nome do arquivo e da pasta onde ele se encontra, está no fato de não precisarmos ficar ajustando separadores de pastas de acordo com o sistema operacional. Enquanto no sistema OS se utiliza “/”, em Windows se utiliza “//”, com o here não há necessidade de preocupação com a troca do caracter.
2 - Nunca salve o workspace
A razão para isso é que, uma vez o workspace salvo e o script modificado, você não saberá mais a linha de comando utilizada para gerar objetos dentro do R. Além disso, rodar todo o script a cada vez que ele é aberto é uma forma de auditoria pessoal da sua rotina de análise. Mas e se os objetos gerados por algum comando são muito grandes, a ponto de se tornar inviável rodar toda vez todas as partes do script? Por exemplo, existem modelos estatísticos que demoram dias para rodar, logo não é interessante esperar dias para poder obter os objetos toda vez que necessitar mexer em alguma análise. Para isso podemos usar a seguinte função:
saveRDS(object = objeto_que_vai_ser_salvo, file = here::here("output", "2021-05-17_modelo_demorado.rds"))Tente substituir o seu objeto e salvar no seu diretório
Para ler o objeto salvo
modelo_demorado <- readRDS(file = here::here("output", "2021-05-17_modelo_demorado.rds"))Formatação de um script
Já experimentou ler um documento de texto formatado com letra Arial, 10, sem espaço entre linhas ou sem pontuação adequada? Até conseguimos lê-lo, a custa da saúde de nossos olhos, na melhor das hipóteses. Com um script é a mesma coisa, e a diferença se torna evidente quando comparamos um script bem formatado com um script mal formatado, conseguimos ler ambos, mas o primeiro facilitará muito nossa vida. Apesar de um script não apresentar normas de formatação algumas regras facilita sua leitura:
- Espaços:
Sempre é desejável utilizar espaços entre operadores lógicos e de atribuição de objetos, por exemplo:
resultado_media <- mean(x = valores) # desejável
resultado_media<-mean(valores) # má formataçãoEspaços depois de vírgulas que separam argumentos
resultado_media <- mean(x = valores, na.rm = TRUE) # recomendado
resultado_media<-mean(x=valores,na.rm=TRUE) # não recomendadoIsso pode parecer pura perfumaria ou preciosismo de programação, mas imagine ter que revisar um script ou função que apresenta mais de 700 linhas de código (o que não é incomum quando estamos rodando rotinas de análises para nossos projetos). Certamente após terminar você terá dores de cabeça.
- Declaração de argumentos
As funções são compostas por argumentos, estes podem estar explicitos ou não nas funções, quando explicitos eles tornam a função muito mais intuitiva que quando implícitos. Mas que saco ter que escrever todos os argumentos de uma função, não é mesmo? Aqui mais um motivo para utilizar o client RStudio. Ao apertar o botão TAB de seu teclado dentro de uma função todos os seus argumentos irão aparecer, basta selecionar qual argumento deseja e ele será inserido dentro da função. Lembrando que isso só é possível com o RStudio.
- Declaração de pacotes Podemos ler os pacotes necessários para as nossas análises na primeira seção de nossos scripts, porém uma prática desejável é declarar explicitamente a função que está sendo utilizada.
Estruturando o script
Busque sempre estruturar o seu script, isso quer dizer separar suas partes. Da mesma forma que um texto científico é dividido em seções, a divisão do script em seções também facilita a sua leitura. A forma mais simples de fazer essa divisão é criando seções, estas seções podem ser criadas utilizando o atalho no seu teclado Shift + Ctrl + R. Isso faz abrir uma janela no RStudio que possibilita inserir o nome desejado para a seção. Tente fazer isso no seu computador para ver o que acontece.
Nomeando os scripts
Nomeamos coisas para que possamos organizá-las de alguma maneira. Portanto, de nada adianta um script bem organizado com um nome completamente contra-intuitivo, ou que não faça sentido algum, dar nome é coisa séria, e, como todos os outros tópicos, podemos seguir algumas regrinhas, mas o mais importante de tudo é que os nossos padrões sejam consistentes e explicados (por exemplo num README).
Jenny Bryan nos fornece aulgumas regras que auxiliam a nomeação de scripts em R e pode ser acessado aqui.